Ensono Stacks Azure Data Platform
The Ensono Stacks Azure Data Platform solution provides a framework for accelerating the deployment of a production-ready modern data platform in Azure.
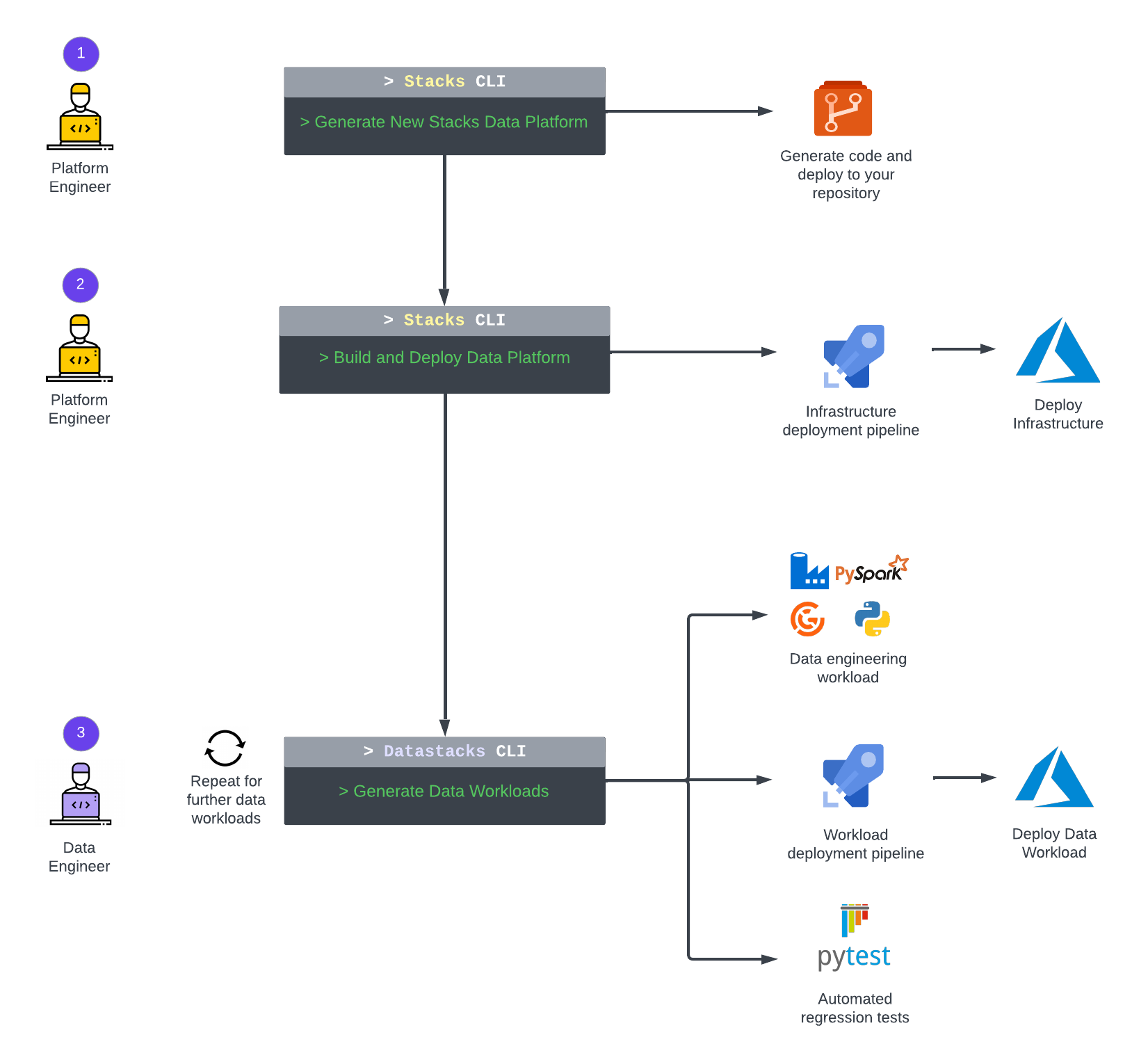
- Use the Ensono Stacks CLI to generate a new data platform project.
- Build and deploy the data platform infrastructure into your Azure environment.
- Accelerate development of data workloads and ELT pipelines with the Datastacks CLI.
The Ensono Stacks Data Platform delivers a modern Lakehouse solution, based upon the medallion architecture, with Bronze, Silver and Gold layers for various stages of data preparation. The platform utilises tools including Azure Data Factory for data ingestion and orchestration, Databricks for data processing and Azure Data Lake Storage Gen2 for data lake storage. It provides a foundation for data analytics and reporting through Microsoft Fabric and Power BI.
Key elements of the solution include:
- Infrastructure as code (IaC) for all infrastructure components (Terraform).
- Deployment pipelines to enable CI/CD and DataOps for the platform and all data workloads.
- Sample data ingest pipelines that transfer data from a source into the landing (Bronze) data lake zone.
- Sample data processing pipelines performing data transformations from Bronze to Silver and Silver to Gold layers.
The solution utilises the Stacks Data Python library, which offers a suite of utilities to support:
- Data transformations using PySpark.
- Frameworks for data quality validations and automated testing.
- The Datastacks CLI - a tool enabling developers to quickly generate new data workloads.
High-level architecture
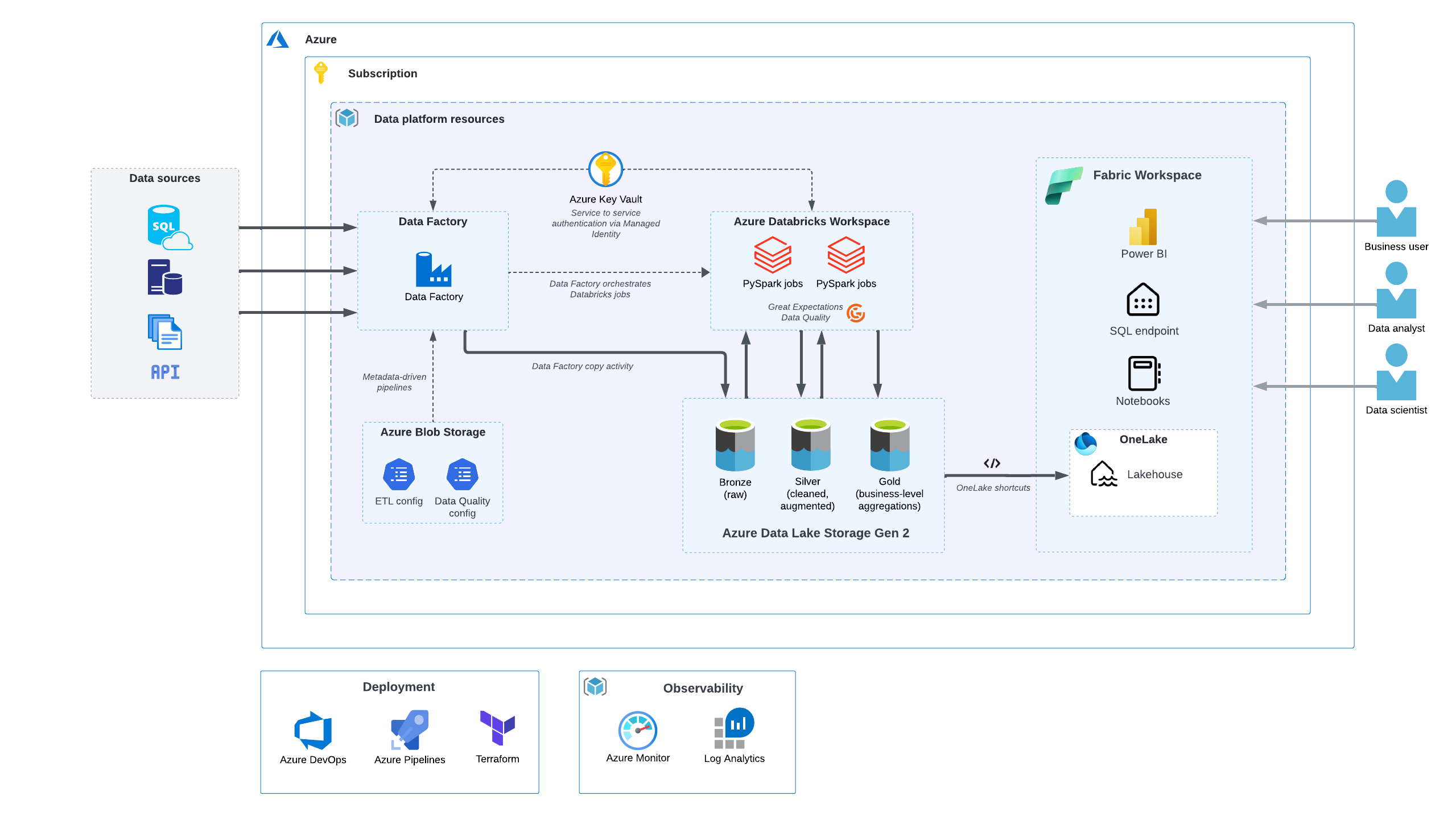
Infrastructure deployed
- Resource Group
- Key Vault
- Azure Data Lake Storage Gen2
- Azure Blob Storage
- Azure Data Factory
- Log Analytics Workspace
- Databricks Workspace
- Azure SQL Database (optional, for testing the platform)
The deployed platform can integrate with Microsoft Fabric to provide a suite of analytics tools and capabilities.
The solution is designed to be deployed within a secure private network - for details see infrastructure and networking.
Data Engineering workloads
Example data engineering workloads are provided, based upon the Datastacks templates:
Each of the ingest and data processing workloads may optionally include data quality checks.