Separation of Concerns
Context
As the size of an application codebase grows, unless the code is structured in a way that makes it straight-forward for it to be evolved then the chances are that any modifications to be made will take longer and new bugs introduced.
This is for a number of reasons, not limited to: -
- No clear view on which code areas need to be modified to effect a business change
- Difficult to replace components or code units as they are not ring-fenced having clear interfaces
- Uncertainty in how the code being modified is actually invoked and executed
- Code blocks that are repeated in numerous places (and may actually differ ever so slightly)
- Difficulty in testing all paths through the codebase for any given change
All of this increases the cognitive load on the developer making it more likely that the quality of the codebase will probably reduce over time.
Solution
The solution to the problems mentioned above are to ensure that there is clear separation of concerns.
Separation of concerns is a design principle for separating a computer program into distinct sections, such that each section addresses a separate concern. For example the business logic of the application is a concern and the user interface is another concern. Changing the user interface should not require changes to business logic and vice versa.
3-Layer Applications
One common way to manage this in a Spring Boot application is to follow the Controller-Service-Repository pattern. One of the big reasons this pattern is so popular is that it does a great job ensuring separation of concerns.
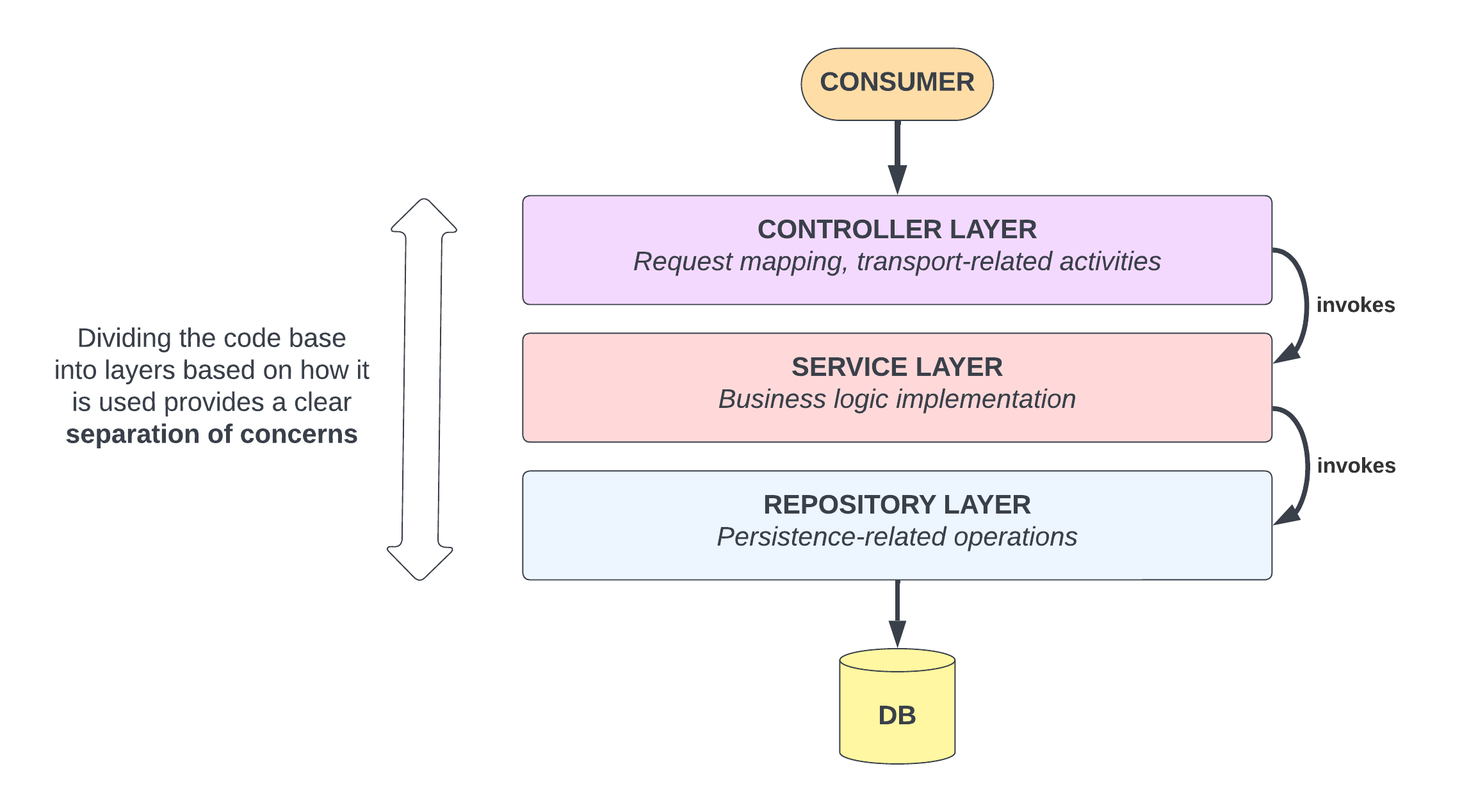
The Controller layer, the top layer in the diagram above, is solely responsible for exposing the functionality so that it can be consumed by external consumers (including, perhaps, a UI component). The Repository layer, at the bottom, is responsible for storing and retrieving some set of data. The Service layer in the middle is where all the business logic should go. If the business logic requires fetching/saving data, it use a Repository. If someone wants to access the business logic from the outside world, they go through a Controller to get there. It is of course perfectly acceptable for one service to call another service.
This sets up a pretty simple separation of concerns. If code is related to storage/retrieval, it should go in the Repository. If it's dealing with exposing functionality to external consumers, it goes in the Controller. Anything unique in the business logic would go in the Service layer. The Repository doesn’t care which component is invoking it; it simply does what it is asked. The Service layer doesn’t care how it gets accessed, it just does its work, using a Repository where required. And the Controller is just passing the work down to the Service layer, so it can stay nice and lean.
Improved Testing
Where this really starts to pay dividends is in the unit testing philosophy.
By having a clean separation of concerns, it is possible to mock adjacent layers and worry about only testing the concerns of that particular layer. Our Controller tests are only worried about response codes and values, and it's easy to mock the service to trigger those conditions. The Service layer can even be tested as a POJO, and by mocking Repository conditions it's possible to test all the business logic therein without having to worry about going through the controller layer to test it.
Implementation Examples
Spring Boot is based heavily on the Spring dependency injection framework. Dependency injection (DI) means that when one component requires the use of another then it is provided to it (auto-magically) by an overarching management container that contains references to all available components (that are declared using Java annotations in the codebase and discovered at startup).
This makes it very easy to create Spring components (essentially just Java classes) that provide this separation of concerns. Of course, it's still possible for a rogue developer to break this pattern and put the code in the wrong places, but having this pattern should help to alleviate this.
Controller Layer
The @RestController annotated class is used to manage the transport-level concerns of the application. As can be seen below, it
manages the REST API path (in this example a HTTP GET request available at URI /thing/{id}) and the shuffling of data from the internal
representation (a Thing domain object) and its external representation (a ThingDTO data transfer object).
It can be seen that a ThingService component is "wired" into the controller class, whose responsibility it is to provide
any business logic (and/or to call peers (other services) or delegate to lower layers).
The code in the controller layer should be as minimal as possible and simply delegate to a service.
@RestController
@RequestMapping("/thing")
public class ThingController {
@Autowired
private ThingService thingService;
@GetMapping("/{id}")
public ResponseEntity<ThingDTO> getThing(@PathVariable("id") UUID id) {
return ResponseEntity.ok(thingService.getThing(id));
}
}
Service Layer
The @Service annotated class is the component where any business logic should be performed. This may include sense-checking
values or performing custom logic. By doing these activities here it makes the unit re-usable across the application, and means
that should the business logic change then it only needs to be modified in one place, and that one place is very clearly related
to the thing (no pun intended) in scope.
It can be seen that a ThingRepository component is "wired" into the service class, whose responsibility it is to manage any
persistence activities such as reading from or writing to a database. Should the business require data to persisted using a different
mechanism (such as to/from a filesystem) then only one repository can be switched out for an alternate (observe that it's an interface in the code).
Note the use of MapStruct in the example below to perform simple bean mapping between domain objects and DTO classes, and vice versa.
@Service
public class ThingService {
@Autowired
private ThingRepository thingRepository;
@Autowired
private ThingMapper thingMapper;
public ThingDTO getThing(UUID id) {
Optional<Thing> optThing = thingRepository.findById(id);
if (optThing.isPresent()) {
// Map between Thing and ThingDTO, probably using MapStruct ...
return thingMapper.toDto(optThing.get());
}
throw new ThingNotFoundException();
}
}
Repository Layer
As discussed above, the @Repository annotated class is the component that manages persistence. Spring Boot provides a number
of standard interfaces out-of-the-box (such as the CrudRepository shown below) which provide methods such as findById(), findAll(),
save(), deleteById() and so on.
@Repository
public interface ThingRepository extends CrudRepository<Thing, UUID> {
// Add any bespoke CRUD methods here
}